xray-epiplexity
xray-epiplexity
数据 = 结构信息 (Epiplexity) + 随机噪声 (Time-bounded Entropy)
S_T(X) = |P*| ← 最优模型程序的长度(可学习的pattern)
H_T(X) = E[log 1/P*(X)] ← 用最优模型编码后剩余的不可预测性
关键约束:观察者算力有限 (T = poly(n))
💡 💡 顿悟
经典信息论假设观察者有无限算力,因此区分不出"有用的结构"和"纯粹的噪声"。给观察者戴上算力枷锁后,数据的信息内容自然分裂为两部分——模型能学到的(epiplexity)和学不到的(time-bounded entropy)。
PROBLEM
❓ 痛点定义
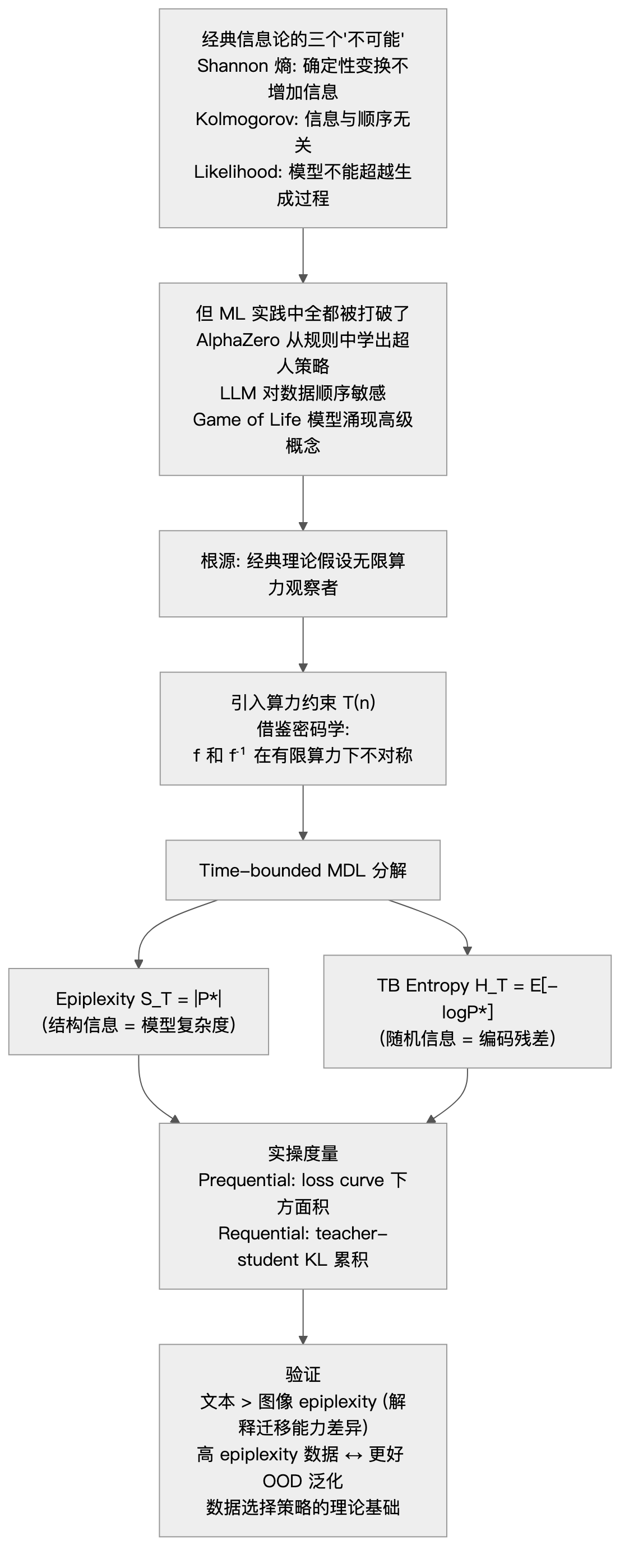
Shannon 信息论和 Kolmogorov 复杂度无法衡量"对有限算力的学习者而言,数据中有多少可学习的结构性信息"。
前人困境:
- Shannon 熵 只描述随机变量的不确定性,确定性对象"信息量为零"——但 AlphaZero 从确定性规则中学出了超人策略
- Kolmogorov 复杂度 不可计算,且假设无限时间运行程序——CSPRNG 输出只有 k 位 Kolmogorov 复杂度,但对多项式时间观察者来说与真随机无法区分
- Sophistication(算法信息论中的"结构度"概念)在理论上捕捉结构,但由于不限计算时间,流体混合、元胞自动机等复杂现象全被"压扁"为简单描述
- Data Processing Inequality 似乎禁止合成数据增加信息——直接与 LLM 训练实践矛盾
⚠️ 核心矛盾
理论说"确定性变换不增加信息",但实践中:合成数据有效、self-play 产生新知、数据顺序影响学习、likelihood 建模能发现比生成过程更复杂的结构。
INSIGHT
💡 💡 顿悟
信息是观察者相对的。同一个对象,对拥有无限算力的观察者和只有多项式时间的观察者来说,"随机"和"有结构"的边界完全不同。
把密码学的核心洞见(one-way function 让正向计算容易、逆向计算困难)桥接到学习理论:函数 f 和它的逆 f⁻¹ 在有限算力下不对称,这种不对称才是信息被"创造"的根源。
📋 关键步骤
- Time-bounded MDL 分解: 给 MDL(最小描述长度)原则加上算力约束。最优模型程序 P 最小化
|P| + E[log 1/P(X)](程序长度 + 编码残差),但限制 P 必须在 T(n) 步内运行。程序长度 |P| 就是 epiplexity,编码残差就是 time-bounded entropy。
- 三个"悖论"的统一消解:
- 悖论1(信息不可创造)→ f(X) 的 MDL_T 可以大于 X 的 MDL_T,因为即使 f 是确定性的且程序短小,f⁻¹ 可能没有短程序(one-way function)。算力约束下,确定性变换可以增加结构信息。
- 悖论2(顺序无关)→ 对有限算力观察者,P(y|x) 和 P(x|y) 的计算难度可以天差地别。同样的联合分布,不同的分解方向产生不同的 epiplexity。
- 悖论3(likelihood = 分布匹配)→ 有限算力模型在拟合简单数据生成过程时,会涌现出比生成规则本身更复杂的内部表示(如 Conway's Game of Life 中的 glider 分类器)。
DELTA
vs SOTA:
| 度量 | Shannon 熵 H | Kolmogorov K | Sophistication | Epiplexity S_T |
|---|---|---|---|---|
| 算力假设 | 无限 | 无限 | 无限 | 有限 T(n) |
| CSPRNG 输出 | k bits | k+c bits | ~0 | ~0 ✓ |
| 确定性变换 | 不增 | 不增(+常数) | 不增 | 可增 ✓ |
| 顺序敏感 | ✗ | ✗ | ✗ | ✓ |
| 可估算 | ✓ | ✗ | ✗ | ✓(loss curve) |
| 对应 ML | 不直接 | 不直接 | 不直接 | 模型权重信息 |
💡 新拼图
- 首次给出"数据价值"的形式化度量——不依赖于下游任务
- 从 model selection 理论翻转为 data selection 理论
- 实验验证:文本数据的 epiplexity 显著高于图像,解释了为什么文本预训练迁移更广
- 提供了评估合成数据价值的理论基础
CRITIQUE
⚠️ 隐形假设
- 核心定理(Theorem 9, 10)依赖于 one-way functions 的存在性——这是密码学的标准假设,但至今未被证明(P≠NP 也未证明)
- 实际度量(loss curve 面积法)使用神经网络作为函数类代理,与理论定义中的"所有 T-time 程序"之间存在 gap
- 假设 prequential coding(在线学习编码)与真正的 MDL-optimal 编码之间的差距"不影响排序"——这只是经验观察,不是理论保证
- Theorem 10 只证明了 epiplexity 可以 Ω(log n) 增长——离实际观察到的 power law scaling 差了几个数量级,理论和实践之间有巨大鸿沟
❓ 未解之谜
- Epiplexity 与 OOD 泛化的关系是相关性不是因果性——高 epiplexity 数据产生的 circuit 不一定对目标任务有用
- 对于特定模型架构(Transformer vs CNN vs MLP),epiplexity 的度量可能完全不同——论文承认了但没解决
- Chain of thought / 多步推理如何影响有效的算力约束 T?理论框架暗示 CoT 可以突破固定深度电路的限制,但没有形式化
- 条件 epiplexity S_T(X|m)(给定预训练模型后的增量信息)的实际度量方法缺失——这正是 post-training 数据选择最需要的
LOGIC FLOW
NAPKIN SKETCH
📄 数据的信息构成 (有限算力视角)
┌─────────────────────────────────┐
│ Total MDL_T │
│ │
│ ┌──────────┐ ┌────────────┐ │
│ │ │ │ │ │
│ │ S_T │ │ H_T │ │
│ │ 结构信息 │ │ 随机噪声 │ │
│ │ (模型) │ │ (残差) │ │
│ │ │ │ │ │
│ │ 可学习 │ │ 不可预测 │ │
│ │ 可迁移 │ │ 纯熵 │ │
│ │ │ │ │ │
│ └──────────┘ └────────────┘ │
└─────────────────────────────────┘
算法代码: S_T ██████░ H_T ░░
自然图像: S_T ████░░░ H_T ███░
CSPRNG: S_T ░░░░░░░ H_T ██████
Config/随机: S_T ░░░░░░░ H_T ██████
░ = 低 █ = 高
关键: 增加算力 T ↑ → 更多"随机"变为"结构"
(CSPRNG 对无限算力观察者: S=0, H=k)
(CSPRNG 对有限算力观察者: S≈0, H≈n >> k)TRANSFER MATRIX
💡 AI 训练数据策略
选高 epiplexity 数据(复杂算法代码 > 配置文件/日志) → Data Value = S_T, not H_T
💡 合成数据理论
确定性变换可以增加对有限算力学习者的结构信息 → Synthetic Data ≠ Zero Information Gain
💡 投资/风险管理类比
市场数据也有"结构信息 vs 噪声"的分离——技术分析试图从有限观察中提取 pattern,等价于有限算力观察者的 epiplexity → Signal Extraction ≈ Epiplexity Estimation